library(knitr)
library(tidyverse)
library(tinytable)4 Writing research
Chapman and Hall/CRC published this book in July 2023. You can purchase that here. This online version has some updates to what was printed.
Prerequisites
- Read By Design: Planning Research on Higher Education, (Light, Singer, and Willett 1990)
- Focus on Chapter 2 “What are your questions”, which provides strategies for developing good research questions.
- Read On Writing Well, (any edition is fine) (Zinsser 1976)
- Focus on Parts I “Principles”, and II “Methods”, which provide a “how-to” for a particularly effective style of writing.
- Read Novelist Cormac McCarthy’s tips on how to write a great science paper, (Savage and Yeh 2019)
- This paper provides specific tips that will improve your writing.
- Read Publication, publication, (G. King 2006)
- This paper details a strategy for moving from a replication to a publishable academic paper.
- Watch Quantitative Editing, (Bronner 2021)
- The video provides strategies for quantitative-based writing based on experience as a quantitative editor at FiveThirtyEight.
- Read Smoking and carcinoma of the lung, (Doll and Hill 1950)
- The paper provides an excellent example of a data section.
- Read How to write usefully (Graham 2020)
- A blog post about writing something true and important that the reader did not already know.
- Read one of the following well-written quantitative papers:
- Asset prices in an exchange economy, (Lucas 1978)
- Individuals, institutions, and innovation in the debates of the French Revolution, (Barron et al. 2018)
- Modeling: optimal marathon performance on the basis of physiological factors, (Joyner 1991)
- On reproducible econometric research, (Koenker and Zeileis 2009)
- Prevented mortality and greenhouse gas emissions from historical and projected nuclear power, (Kharecha and Hansen 2013)
- Seeing like a market, (Fourcade and Healy 2017)
- Simpson’s paradox and the hot hand in basketball, (Wardrop 1995)
- Some studies in machine learning using the game of checkers, (Samuel 1959)
- Statistical methods for assessing agreement between two methods of clinical measurement, (Bland and Altman 1986)
- Surgical Skill and Complication Rates after Bariatric Surgery, (Birkmeyer et al. 2013)
- The mundanity of excellence: An ethnographic report on stratification and Olympic swimmers, (Chambliss 1989)
- The probable error of a mean, (Student 1908)
- Read one of the following articles from The New Yorker:
- Funny Like a Guy, Tad Friend, 4 April 2011
- Going the Distance, David Remnick, 19 January 2014
- How the First Gravitational Waves Were Found, Nicola Twilley, 11 February 2016
- Happy Feet, Alexandra Jacobs, 7 September 2009
- Levels of the Game, John McPhee, 31 May 1969
- Reporting from Hiroshima, John Hersey, 23 August 1946
- The Catastrophist, Elizabeth Kolbert, 22 June 2009
- The Quiet German, George Packer, 24 November 2014
- The Pursuit of Beauty, Alec Wilkinson, 1 February 2015
- Read one of the following articles from other publications:
- Blades of Glory, Holly Anderson, Grantland
- Born to Run, Walt Harrington, The Washington Post
- Dropped, Jason Fagone, Grantland
- Federer as Religious Experience, David Foster Wallace, The New York Times Magazine
- Generation Why?, Zadie Smith, The New York Review of Books
- One hundred years of arm bars, David Samuels, Grantland
- Out in the Great Alone, Brian Phillips, ESPN
- Pearls Before Breakfast, Gene Weingarten, The Washington Post
- Resurrecting The Champ, J.R. Moehringer, Los Angeles Times
- The Cult of “Jurassic Park”, Bryan Curtis, Grantland
- The House that Hova Built, Zadie Smith, The New York Times
- The Re-Education of Chris Copeland, Flinder Boyd, SB Nation
- The Sea of Crisis, Brian Phillips, Grantland
- The Webb Space Telescope Will Rewrite Cosmic History. If It Works., Natalie Wolchover, Quanta Magazine
Key concepts and skills
- Writing is a critical skill—perhaps the most important—of all the skills required to analyze data. The only way to get better at writing is to write, ideally every day.
- When we write, although the benefits typically accrue to ourselves, we must nonetheless write for the reader. This means having one main message that we want to communicate, and thinking about where they are, rather than where we are.
- We want to get to a first draft as quickly as possible. Even if it is horrible, the difference between a first draft existing and not is enormous. At that point we start to rewrite. When doing so we aim to maximize clarity, often by removing unnecessary words.
- We typically begin with some area of interest and then develop research questions, datasets, and analysis in an iterative way. Through this process we come to a better understanding of what we are doing.
Software and packages
knitr(Xie 2023)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
4.1 Introduction
If you want to be a writer, you must do two things above all others: read a lot and write a lot. There’s no way around these two things that I’m aware of, no shortcut.
S. King (2000, 145)
We predominately tell stories with data by writing them down. Writing allows us to communicate efficiently. It is also a way to work out what we believe and allows us to get feedback on our ideas. Effective papers are tightly written and well-organized, which makes their story flow well. Proper sentence structure, spelling, vocabulary, and grammar are important because they remove distractions and enable each aspect of the story to be clearly articulated.
This chapter is about writing. By the end of it, you will have a better idea of how to write short, detailed, quantitative papers that communicate what you want them to, and do not waste the reader’s time. We write for the reader, not for ourselves. Specifically, we write to be useful to the reader. This means clearly communicating something new, true, and important (Graham 2020). That said, the greatest benefit of writing nonetheless often accrues to the writer, even when we write for our audience. This is because the process of writing is a way to work out what we think and how we came to believe it.
Aspects of this chapter can feel a little like a list. It may be that you go through those aspects quickly initially, and then return to them as needed.
4.2 Writing
The way to do a piece of writing is three or four times over, never once. For me, the hardest part comes first, getting something—anything—out in front of me. Sometimes in a nervous frenzy I just fling words as if I were flinging mud at a wall. Blurt out, heave out, babble out something—anything—as a first draft.
McPhee (2017, 159)
The process of writing is a process of rewriting. The critical task is to get to a first draft as quickly as possible. Until that complete first draft exists, it is useful to try to not to delete, or even revise, anything that was written, regardless of how bad it may seem. Just write. (This advice is directed at less-experienced writers. As you get more experience, you may find that your approach changes.)
One of the most intimidating stages is a blank page, and we deal with this by immediately adding headings such as: “Introduction”, “Data”, “Model”, “Results”, and “Discussion”. And then adding fields in the top matter for the various bits and pieces that are needed, such as “title”, “date”, “author”, and “abstract”. This creates a generic outline, which will play the role of mise en place for the paper. By way of background, mise en place is a preparatory phase in a professional kitchen when ingredients are sorted, prepared, and arranged for easy access. This ensures that everything that is needed is available without unnecessary delay. Putting together an outline plays the same role when writing quantitative papers, and is akin to placing on the counter, the ingredients that we will use to prepare dinner (McPhee 2017).
Having established this generic outline, we need to develop an understanding of what we are exploring through thinking deeply about our research question. In theory, we develop a research question, answer it, and then do all the writing; but that rarely actually happens (Franklin 2005). Instead, we typically have some idea of the question and the shape of an answer, and these become less vague as we write. This is because it is through the process of writing that we refine our thinking (S. King 2000, 131). Having put down some thoughts about the research question, we can start to add dot points in each of the sections, adding sub-sections with informative sub-headings as needed. We then go back and expand those dot points into paragraphs. While we do this our thinking is influenced by a web of other researchers, but also other aspects such as our circumstances and environment (Latour 1996).
While writing the first draft you should ignore the feeling that you are not good enough, or that it is impossible. Just write. You need words on paper, even if they are bad, and the first draft is when you accomplish this. Remove distractions and focus on writing. Perfectionism is the enemy, and should be set aside. Sometimes this can be accomplished by getting up very early to write, by creating a deadline, or forming a writing group. Creating a sense of urgency can be useful and one option is to not bother with adding proper citations as you go, which could slow you down, and instead just add something like “[TODO: CITE R HERE]”. Do similar with graphs and tables. That is, include textual descriptions such as “[TODO: ADD GRAPH THAT SHOWS EACH COUNTRY OVER TIME HERE]” instead of actual graphs and tables. Focus on adding content, even if it is bad. When this is all done, a first draft exists.
This first draft will be poorly written and far from great. But it is by writing a bad first draft that you can get to a good second draft, a great third draft, and eventually excellence (Lamott 1994, 20). That first draft will be too long, it will not make sense, it will contain claims that cannot be supported, and some claims that should not be. If you are not embarrassed by your first draft, then you have not written it quickly enough.
Use the “delete” key extensively, as well as “cut” and “paste”, to turn that first draft into a second. Print the draft and using a red pen to move or remove words, sentences, and entire paragraphs, is especially helpful. The process of going from a first draft to a second draft is best done in one sitting, to help with the flow and consistency of the story. One aspect of this first rewrite is enhancing the story that we want to tell. Another aspect is taking out everything that is not the story (S. King 2000, 57).
It can be painful to remove work that seems good even if it does not quite fit into what the draft is becoming. One way to make this less painful is to make a temporary document, perhaps named “debris.qmd”, to save these unwanted paragraphs instead of immediately deleting them. Another strategy is to comment out the paragraphs. That way you can still look at the raw file and notice aspects that could be useful.
As you go through what was written in each of the sections try to bring some sense to it with special consideration to how it supports the story that is developing. This revision process is the essence of writing (McPhee 2017, 160). You should also fix the references, and add the real graphs and tables. As part of this rewriting process, the paper’s central message tends to develop, and the answers to the research questions tend to become clearer. At this point, aspects such as the introduction can be returned to and, finally, the abstract. Typos and other issues affect the credibility of the work. So these should be fixed as part of the second draft.
At this point the draft is starting to become sensible. The job is to now make it brilliant. Print it and again go through it on paper. Try to remove everything that does not contribute to the story. At about this stage, you may start to get too close to the paper. This is a great opportunity to give it to someone else for their comments. Ask for feedback about what is weak about the story. After addressing these, it can be helpful to go through the paper once more, this time reading it aloud. A paper is never “done” and it is more that at a certain point you either run out of time or become sick of the sight of it.
4.3 Asking questions
Both qualitative and quantitative approaches have their place. In this book we focus on quantitative approaches. Nonetheless qualitative research is important, and often the most interesting work has a little of both. When conducting quantitative analysis, we are subject to issues such as data quality, measurement, and relevance. We are often especially interested in trying to tease out causality. Regardless, we are trying to learn something about the world. Our research questions need to take this all into account.
Broadly, and at the risk of over-simplification, there are two ways to go about research:
- data-first; or
- question-first.
But it is not a binary, and often research proceeds by iterating between data and questions, organized around a research puzzle (Gustafsson and Hagström 2017). Light, Singer, and Willett (1990, 39) describe this approach as a spiral of \(\mbox{theory}\rightarrow\mbox{data}\rightarrow\mbox{theory}\rightarrow\mbox{data}\), etc. For instance, a question-first approach could be theory-driven or data-driven, as could a data-first approach. An alternative framing is to compare an inductive, or specific-to-general, approach with a deductive, or general-to-specific, approach to research.
Consider two examples:
- Mok et al. (2022) examine eight billion unique listening events from 100,000 Spotify users to understand how users explore content. They find a clear relationship between age and behavior, with younger users exploring unknown content less than older users, despite having more diverse consumption. While it is clear that research questions around discovery and exploration drive this paper, it would not have been possible without access to this dataset. There likely would have been an iterative process where potential research questions and potential datasets were considered, before the ultimate match.
- Think of wanting to explore the neonatal mortality rate (NMR), which was introduced in Chapter 2. One might be interested in what NMR could look like in Sub-Saharan Africa in 20 years. This would be question-first. But within this, there could be: theory-driven aspects, such as what do we expect based on biological relationships with other quantities; or data-driven aspects such as collecting as much data as possible to make forecasts. An alternative, purely data-driven approach would be having access to the NMR and then working out what is possible.
4.3.1 Data-first
When being data-first, the main issue is working out the questions that can be reasonably answered with the available data. When deciding what these are, it is useful to consider:
- Theory: Is there a reasonable expectation that there is something causal that could be determined? For instance, Mark Christensen used to joke that if the question involved charting the stock market, then it might be better to hark back to The Odyssey and read bull entrails on a fire, because at least that way you would have something to eat at the end of the day. Questions usually need to have some plausible theoretical underpinning to help avoid spurious relationships. One way to develop theory, given data, is to consider “of what is this an instance?” (Rosenau 1999, 7). Following that approach, one tries to generalize beyond the specific setting. For instance, thinking of some particular civil war as an instance of all civil wars. The benefit of this is it focuses attention on the general attributes needed for building theory.
- Importance: There are plenty of trivial questions that can be answered, but it is important to not waste our time or that of the reader. Having an important question can also help with motivation when we find ourselves in, say, the fourth straight week of cleaning data and debugging code. In industry it can also make it easier to attract talented employees and funding. That said, a balance is needed; the question needs to have a decent chance of being answered. Attacking a generation-defining question might be best broken into chunks.
- Availability: Is there a reasonable expectation of additional data being available in the future? This could allow us to answer related questions and turn one paper into a research agenda.
- Iteration: Is this something that could be run multiple times, or is it a once-off analysis? If it is the former, then it becomes possible to start answering specific research questions and then iterate. But if we can only get access to the data once then we need to think about broader questions.
There is a saying, sometimes attributed to Xiao-Li Meng, that all of statistics is a missing data problem. And so paradoxically, another way to ask data-first questions is to think about the data we do not have. For instance, returning to the neonatal and maternal mortality examples discussed earlier one problem is that we do not have complete cause of death data. If we did, then we could count the number of relevant deaths. (Castro et al. (2023) remind us that this simplistic hypothetical would be complicated in reality because there are sometimes causes of death that are not independent of other causes.) Having established some missing data problem, we can take a data-driven approach. We look at the data we do have, and then ask research questions that speak to the extent that we can use that to approximate our hypothetical dataset.
Shoulders of giants
Xiao-Li Meng is the Whipple V. N. Jones Professor of Statistics at Harvard University. After earning a PhD in Statistics from Harvard University in 1990 he was appointed as an assistant professor at the University of Chicago where he was promoted to professor in 2000. He moved to Harvard in 2001, serving as chair of the statistics department between 2004 and 2012. He has published on a wide range of topics including missing data—Meng (1994) and Meng (2012)—and data quality—Meng (2018). He was awarded the COPSS Presidents’ Award in 2001.
One way that some researchers are data-first is that they develop a particular expertise in the data of some geographical or historical circumstance. For instance, they may be especially knowledgeable about, say, the present-day United Kingdom, or late nineteenth century Japan. They then look at the questions that other researchers are asking in other circumstances, and bring their data to that question. For instance, it is common to see a particular question initially asked for the United States, and then a host of researchers answer that same question for the United Kingdom, Canada, Australia, and many other countries.
There are a number of negatives to data-first research, including the fact that it can be especially uncertain. It can also struggle for external validity because there is always a worry about a selection effect.
A variant of data-driven research is model-driven research. Here a researcher becomes an expert on some particular statistical approach and then applies that approach to appropriate contexts.
4.3.2 Question-first
When trying to be question-first, there is the inverse issue of being concerned about data availability. The “FINER framework” is used in medicine to help guide the development of research questions. It recommends asking questions that are: Feasible, Interesting, Novel, Ethical, and Relevant (Hulley et al. 2007). Farrugia et al. (2010) build on FINER with PICOT, which recommends additional considerations: Population, Intervention, Comparison group, Outcome of interest, and Time.
It can feel overwhelming trying to write out a question. One way to go about it is to ask a very specific question. Another is to decide whether we are interested in descriptive, predictive, inferential, or causal analysis. These then lead to different types of questions. For instance:
- descriptive analysis: “What does \(x\) look like?”;
- predictive analysis: “What will happen to \(x\)?”;
- inferential: “How can we explain \(x\)?”; and
- causal: “What impact does \(x\) have on \(y\)?”.
Each of these have a role to play. Since the credibility revolution (Angrist and Pischke 2010), causal questions answered with a particular approach have been predominant. This has brought some benefit, but not without cost. Descriptive analysis can be just as, indeed sometimes more, illuminating, and is critical (Sen 1980). The nature of the question being asked matters less than being genuinely interested in answering it.
Time will often be constrained, possibly in an interesting way and this can guide the specifics of the research question. If we are interested in the effect of a celebrity’s announcements on the stock market, then that can be done by looking at stock prices before and after the announcement. But what if we are interested in the effect of a cancer drug on long term outcomes? If the effect takes 20 years, then we must either wait a while, or we need to look at people who were treated twenty years ago. We then have selection effects and different circumstances compared to if we were to administer the drug today. Often the only reasonable thing to do is to build a statistical model, but that brings other issues.
4.4 Answering questions
4.4.1 Counterfactuals and bias
The creation of a counterfactual is often crucial when answering questions. A counterfactual is an if-then statement in which the “if” is false. Consider the example of Humpty Dumpty in Through the Looking-Glass by Lewis Carroll:
“What tremendously easy riddles you ask!” Humpty Dumpty growled out. “Of course I don’t think so! Why, if ever I did fall off—which there’s no chance of—but if I did—” Here he pursed his lips and looked so solemn and grand that Alice could hardly help laughing. “If I did fall,” he went on, “The King has promised me—with his very own mouth-to-to-” “To send all his horses and all his men,” Alice interrupted, rather unwisely.
Carroll (1871)
Humpty is satisfied with what would happen if he were to fall off, even though he is convinced that this would never happen. It is this comparison group that often determines the answer to a question. For instance, in Chapter 15 we consider the effect of VO2 max on a cyclist’s chance of winning a race. If we compare over the general population then it is an important variable. But if we only compare over well-trained athletes, then it is less important, because of selection.
Two aspects of the data to be especially aware of when deciding on a research question are selection bias and measurement bias.
Selection bias occurs when the results depend on who is in the sample. One of the pernicious aspects of selection bias is that we need to know about its existence in order to do anything about it. But many default diagnostics will not identify selection bias. In A/B testing, which we discuss in Chapter 8, A/A testing is a slight variant where we create groups and compare them before imposing a treatment (hence the A/A nomenclature). This effort to check whether the groups are initially the same, can help to identify selection bias. More generally, comparing the properties of the sample, such as age-group, gender, and education, with characteristics of the population can assist as well. But the fundamental problem with selection bias and observational data is that we know people about whom we have data are different in at least one way to those about whom we do not! But we do not know in what other ways they may be different.
Selection bias can pervade many aspects of our analysis. Even a sample that is initially representative may become biased over time. For instance, survey panels, that we discuss in Chapter 6, need to be updated from time to time because the people who do not get anything out of it stop responding.
Another bias to be aware of is measurement bias, which occurs when the results are affected by how the data were collected. A common example of this is if we were to ask respondents their income, then we may get different answers in-person compared with an online survey.
4.4.2 Estimands
We will typically be interested in using data to answer our question and it is important that we are clear about specifics. For instance, we might be interested in the effect of smoking on life expectancy. In that case, there is some true effect, which we can never know, and that true effect is called the “estimand” (Little and Lewis 2021). Defining the estimand at some point in the paper, ideally in the introduction, is critical (Lundberg, Johnson, and Stewart 2021). This is because it is easy to slightly change some specific aspect of the analysis plan and end up accidentally estimating something different (Kahan et al. 2022). They are beginning to be required by some medicine regulators (Kahan et al. 2024). For an estimand we are looking for a clear description of what the effect represents (Kahan et al. 2023). An “estimator” is a process by which we use the data that we have available to generate an “estimate” of the “estimand”. Efron and Morris (1977) provide a discussion of estimators and related concerns.
Bueno de Mesquita and Fowler (2021, 94) describe the relationship between an estimate and an estimand as:
\[ \mbox{Estimate = Estimand + Bias + Noise} \]
Bias refers to issues with an estimator systematically providing estimates that are different from the estimand, while noise refers to non-systematic differences. For instance, consider a standard Normal distribution. We might be interested in understanding the average, which would be our estimand. We know (in a way that we can never with real data) that the estimand is zero. Let us draw ten times from that distribution. One estimator we could use to produce an estimate is: sum the draws and divide by the number of draws. Another is to order the draws and find the middle observation. To be more specific, we will simulate this situation (Table 4.1).
set.seed(853)
tibble(
num_draws = c(
rep(10, times = 10),
rep(100, times = 100),
rep(1000, times = 1000),
rep(10000, times = 10000)
),
draw = rnorm(
n = length(num_draws),
mean = 0,
sd = 1)
) |>
summarise(
estimator_one = sum(draw) / unique(num_draws),
estimator_two = sort(draw)[round(unique(num_draws) / 2, 0)],
.by = num_draws
) |>
tt() |>
style_tt(j = 2:3, align = "r") |>
format_tt(digits = 2, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("Number of draws", "Estimator one", "Estimator two"))| Number of draws | Estimator one | Estimator two |
|---|---|---|
| 10 | -0.58 | -0.82 |
| 100 | -0.06 | -0.07 |
| 1,000 | 0.06 | 0.04 |
| 10,000 | -0.01 | -0.01 |
As the number of draws increases, the effect of noise is removed, and our estimates illustrate the bias of our estimators. In this example, we know what the truth is, but when considering real data it can be more difficult to know what to do. Hence the importance of being clear about what the estimand is, before turning to generating estimates.
4.4.3 Directed Acyclic Graphs
When we are thinking about the variables we will use to answer our question, it can help to be specific about what we mean. It is easy to get caught up in observational data and trick ourselves. We should think hard, and to use all the tools available to us. One framework that can help with thinking hard about our data is the use of directed acyclic graphs (DAG). DAGs are a fancy name for a flow diagram and involve drawing arrows and lines between the variables to indicate the relationship between them.
To construct them we use Graphviz, which is an open-source package for graph visualization and is built into Quarto. The code needs to be wrapped in a “dot” chunk rather than “R”, and the chunk options are set with “//|” instead of “#|”. Alternatives that do not require this include the use of DiagrammeR (Iannone 2022) and ggdag (Barrett 2021). We provide the whole chunk for the first DAG, but then, only provide the code for the others.
```{dot}
//| label: fig-dot-firstdag-quarto
//| fig-cap: "We expect a causal relationship between x and y, where x influences y"
//| fig-width: 4
digraph D {
node [shape=plaintext, fontname = "helvetica"];
{rank=same x y};
x -> y;
}
```In Figure 4.1, we are saying that we think x causes y.
We could build another DAG where the situation is less clear. To make the examples a little easier to follow, we will switch to thinking about a hypothetical relationship between income and happiness, with consideration of variables that could affect that relationship. In this first one we consider the relationship between income and happiness, along with education (Figure 4.2).
digraph D {
node [shape=plaintext, fontname = "helvetica"];
a [label = "Income"];
b [label = "Happiness"];
c [label = "Education"];
{ rank=same a b};
a->b;
c->{a, b};
}In Figure 4.2, we think income causes happiness. But we also think that education causes happiness, and that education also causes income. That relationship is a “backdoor path”, and failing to adjust for education in a regression could overstate the extent of the relationship, or even create a spurious relationship, between income and happiness in our analysis. That is, we may think that changes in income are causing changes in happiness, but it could be that education is changing them both. That variable, in this case, education, is called a “confounder”.
Hernán and Robins (2023, 83) discuss an interesting case where a researcher was interested in whether one person looking up at the sky makes others look up at the sky also. There was a clear relationship between the responses of both people. But it was also the case that there was noise in the sky. It was unclear whether the second person looked up because the first person looked up, or they both looked up because of the noise. When using experimental data, randomization allows us to avoid this concern, but with observational data we cannot rely on that. It is also not the case that bigger data necessarily get around this problem for us. Instead, we should think carefully about the situation, and DAGs can help with that.
If there are confounders, but we are still interested in causal effects, then we need to adjust for them. One way is to include them in the regression. But the validity of this requires several assumptions. In particular, Gelman and Hill (2007, 169) warn that our estimate will only correspond to the average causal effect in the sample if we include all of the confounders and have the right model. Putting the second requirement to one side, and focusing only on the first, if we do not think about and observe a confounder, then it can be difficult to adjust for it. And this is an area where both domain expertise and theory can bring considerable weight to an analysis.
In Figure 4.3 we again consider that income causes happiness. But, if income also causes children, and children also cause happiness, then we have a situation where it would be tricky to understand the effect of income on happiness.
digraph D {
node [shape=plaintext, fontname = "helvetica"];
a [label = "Income"];
b [label = "Happiness"];
c [label = "Children"];
{ rank=same a b};
a->{b, c};
c->b;
}In Figure 4.3, children is called a “mediator” and we would not adjust for it if we were interested in the effect of income on happiness. If we were to adjust for it, then some of what we are attributing to income, would be due to children.
Finally, in Figure 4.4 we have yet another similar situation, where we think that income causes happiness. But this time both income and happiness also cause exercise. For instance, if you have more money then it may be easier to exercise, but also it may be easier to exercise if you are happier.
digraph D {
node [shape=plaintext, fontname = "helvetica"];
a [label = "Income"];
b [label = "Happiness"];
c [label = "Exercise"];
{ rank=same a b};
a->{b c};
b->c;
}In this case, exercise is called a “collider” and if we were to condition on it, then we would create a misleading relationship. Income influences exercise, but a person’s happiness also affects this. Exercise is a collider because both the predictor and outcome variable of interest influence it.
We will be clear about this: we must create the DAG ourselves, in the same way that we must put together the model ourselves. There is nothing that will create it for us. This means that we need to think carefully about the situation. Because it is one thing to see something in the DAG and then do something about it, but it is another to not even know that it is there. McElreath ([2015] 2020, 180) describes these as haunted DAGs. DAGs are helpful, but they are just a tool to help us think deeply about our situation.
When we are building models, it can be tempting to include as many predictor variables as possible. DAGs show clearly why we need to be more thoughtful. For instance, if a variable is a confounder, then we would want to adjust for it, whereas if a variable was a collider then we would not. We can never know the truth, and we are informed by aspects such as theory, what we are interested in, research design, limitations of the data, or our own limitations as researchers, to name a few. Knowing the limits is as important as reporting the model. Data and models with flaws are still useful, if you acknowledge those flaws. The work of thinking about a situation is never done, and relies on others, which is why we need to make all our work as reproducible as possible.
4.5 Components of a paper
I had not indeed published anything before I commenced The Professor, but in many a crude effort, destroyed almost as soon as composed, I had got over any such taste as I might once have had for ornamented and redundant composition, and come to prefer what was plain and homely.
The Professor (Brontë 1857)
We discuss the following components: title, abstract, introduction, data, results, discussion, figures, tables, equations, and technical terms.1 Throughout the paper try to be as brief and specific as possible. Most readers will not get past the title. Almost no one will read more than the abstract. Section and sub-section headings, as well as graph and table captions should work on their own, without the surrounding text, because that type of skimming is how many people read papers (Keshav 2007).
4.5.1 Title
A title is the first opportunity that we have to engage our reader in our story. Ideally, we are able to tell our reader exactly what we found. Effective titles are critical because otherwise papers could be ignored by readers. While a title does not have to be “cute”, it does need to be meaningful. This means it needs to make the story clear.
One example of a title that is good enough is “On the 2016 Brexit referendum”. This title is useful because the reader knows what the paper is about. But it is not particularly informative or enticing. A slightly better title could be “On the Vote Leave outcome in the 2016 Brexit referendum”. This variant adds informative specificity. We argue the best title would be something like “Vote Leave outperforms in rural areas in the 2016 Brexit referendum: Evidence from a Bayesian hierarchical model”. Here the reader knows the approach of the paper and also the main take-away.
We will consider a few examples of particularly effective titles. Hug et al. (2019) use “National, regional, and global levels and trends in neonatal mortality between 1990 and 2017, with scenario-based projections to 2030: a systematic analysis”. Here it is clear what the paper is about and the methods that are used. R. Alexander and Alexander (2021) use “The Increased Effect of Elections and Changing Prime Ministers on Topics Discussed in the Australian Federal Parliament between 1901 and 2018”. The main finding is, along with a good deal of information about what the content will be, clear from the title. M. Alexander, Kiang, and Barbieri (2018) use “Trends in Black and White Opioid Mortality in the United States, 1979–2015”; Frei and Welsh (2022) use “How the closure of a US tax loophole may affect investor portfolios”. Possibly one of the best titles ever is Bickel, Hammel, and O’Connell (1975) “Sex Bias in Graduate Admissions: Data from Berkeley: Measuring bias is harder than is usually assumed, and the evidence is sometimes contrary to expectation”, which we return to in Chapter 15.
A title is often among the last aspects of a paper to be finalized. While getting through the first draft, we typically use a working title that gets the job done. We then refine it over the course of redrafting. The title needs to reflect the final story of the paper, and this is not usually something that we know at the start. We must strike a balance between getting our reader interested enough to read the paper, and conveying enough of the content so as to be useful (Hayot 2014). Two excellent examples are The History of England from the Accession of James the Second by Thomas Babington Macaulay, and A History of the English-Speaking Peoples by Winston Churchill. Both are clear about what the content is, and, for their target audience, spark interest.
One specific approach is the form: “Exciting content: Specific content”, for instance, “Returning to their roots: Examining the performance of Vote Leave in the 2016 Brexit referendum”. Kennedy and Gelman (2021) provide a particularly nice example of this approach with “Know your population and know your model: Using model-based regression and poststratification to generalize findings beyond the observed sample”, as does Craiu (2019) with “The Hiring Gambit: In Search of the Twofer Data Scientist”. A close variant of this is “A question? And an approach”. For instance, Cahill, Weinberger, and Alkema (2020) with “What increase in modern contraceptive use is needed in FP2020 countries to reach 75% demand satisfied by 2030? An assessment using the Accelerated Transition Method and Family Planning Estimation Model”. As you gain experience with this variant, it becomes possible to know when it is appropriate to drop the answer part yet remain effective, such as Briggs (2021) with “Why Does Aid Not Target the Poorest?”. Another specific approach is “Specific content then broad content” or the inverse. For instance, “Rurality, elites, and support for Vote Leave in the 2016 Brexit referendum” or “Support for Vote Leave in the 2016 Brexit referendum, rurality and elites”. This approach is used by Tolley and Paquet (2021) with “Gender, municipal party politics, and Montreal’s first woman mayor”.
Sometimes it is possible to include a subtitle. When this is possible, a great way to take advantage of this is to use it to include some detail of the main quantitative result that you found. Getting the right level of detail and abstraction about that result is difficult and will require re-writing and getting other’s opinions.
4.5.2 Abstract
For a ten-to-fifteen-page paper, a good abstract is a three-to-five sentence paragraph. For a longer paper the abstract can be slightly longer. The abstract needs to specify the story of the paper. It must also convey what was done and why it matters. To do so, an abstract typically touches on the context of the work, its objectives, approach, and findings.
More specifically, a good recipe for an abstract is: first sentence: specify the general area of the paper and encourage the reader; second sentence: specify the dataset and methods at a general level; third sentence: specify the headline result; and a fourth sentence about implications.
We see this pattern in a variety of abstracts. For instance, Tolley and Paquet (2021) draw in the reader with their first sentence by mentioning the election of the first woman mayor in 400 years. The second sentence is clear about what is done in the paper. The third sentence tells the reader how it is done i.e. a survey, and the fourth sentence adds some detail. The fifth and final sentence makes the main take-away clear.
In 2017, Montreal elected Valérie Plante, the first woman mayor in the city’s 400-year history. Using this election as a case study, we show how gender did and did not influence the outcome. A survey of Montreal electors suggests that gender was not a salient factor in vote choice. Although gender did not matter much for voters, it did shape the organization of the campaign and party. We argue that Plante’s victory can be explained in part by a strategy that showcased a less leader-centric party and a degendered campaign that helped counteract stereotypes about women’s unsuitability for positions of political leadership.
Similarly, Beauregard and Sheppard (2021) make the broader environment clear within the first two sentences, and the specific contribution of this paper to that environment. The third and fourth sentences make the data source and main findings clear. The fifth and sixth sentences add specificity that would be of interest to likely readers of this abstract i.e. academic political scientists. In the final sentence, the position of the authors is made clear.
Previous research on support for gender quotas focuses on attitudes toward gender equality and government intervention as explanations. We argue the role of attitudes toward women in understanding support for policies aiming to increase the presence of women in politics is ambivalent—both hostile and benevolent forms of sexism contribute in understanding support, albeit in different ways. Using original data from a survey conducted on a probability-based sample of Australian respondents, our findings demonstrate that hostile sexists are more likely to oppose increasing of women’s presence in politics through the adoption of gender quotas. Benevolent sexists, on the other hand, are more likely to support these policies than respondents exhibiting low levels of benevolent sexism. We argue this is because benevolent sexism holds that women are pure and need protection; they do not have what it takes to succeed in politics without the assistance of quotas. Finally, we show that while women are more likely to support quotas, ambivalent sexism has the same relationship with support among both women and men. These findings suggest that aggregate levels of public support for gender quotas do not necessarily represent greater acceptance of gender equality generally.
Another excellent example of an abstract is Sides, Vavreck, and Warshaw (2021). In just five sentences, they make it clear what they do, how they do it, what they find, and why it is important.
We provide a comprehensive assessment of the influence of television advertising on United States election outcomes from 2000–2018. We expand on previous research by including presidential, Senate, House, gubernatorial, Attorney General, and state Treasurer elections and using both difference-in-differences and border-discontinuity research designs to help identify the causal effect of advertising. We find that televised broadcast campaign advertising matters up and down the ballot, but it has much larger effects in down-ballot elections than in presidential elections. Using survey and voter registration data from multiple election cycles, we also show that the primary mechanism for ad effects is persuasion, not the mobilization of partisans. Our results have implications for the study of campaigns and elections as well as voter decision making and information processing.
The best abstracts will have such a high content to words ratio that they may even feel a little terse. For instance, in the abstract of Touvron et al. (2023), there is not a word that is wasted and they communicate a large amount of information in only four sentences.
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
Kasy and Teytelboym (2023) provide an excellent example of a more statistical abstract. They clearly identify what they do and why it is important.
We consider an experimental setting in which a matching of resources to participants has to be chosen repeatedly and returns from the individual chosen matches are unknown but can be learned. Our setting covers two-sided and one-sided matching with (potentially complex) capacity constraints, such as refugee resettlement, social housing allocation, and foster care. We propose a variant of the Thompson sampling algorithm to solve such adaptive combinatorial allocation problems. We give a tight, prior-independent, finite-sample bound on the expected regret for this algorithm. Although the number of allocations grows exponentially in the number of matches, our bound does not. In simulations based on refugee resettlement data using a Bayesian hierarchical model, we find that the algorithm achieves half of the employment gains (relative to the status quo) that could be obtained in an optimal matching based on perfect knowledge of employment probabilities.
Finally, Briggs (2021) begins with a claim that seems unquestionably true. In the second sentence he then says that it is false! The third sentence specifies the extent of this claim, and the fourth sentence details how he comes to this position, before providing more detail. The final two sentences speak broader implications and importance.
Foreign-aid projects typically have local effects, so they need to be placed close to the poor if they are to reduce poverty. I show that, conditional on local population levels, World Bank (WB) project aid targets richer parts of countries. This relationship holds over time and across world regions. I test five donor-side explanations for pro-rich targeting using a pre-registered conjoint experiment on WB Task Team Leaders (TTLs). TTLs perceive aid-receiving governments as most interested in targeting aid politically and controlling implementation. They also believe that aid works better in poorer or more remote areas, but that implementation in these areas is uniquely difficult. These results speak to debates in distributive politics, international bargaining over aid, and principal-agent issues in international organizations. The results also suggest that tweaks to WB incentive structures to make ease of project implementation less important may encourage aid to flow to poorer parts of countries.
Nature, a scientific journal, provides a guide for constructing an abstract. They recommend a structure that results in an abstract of six parts and adds up to around 200 words:
- An introductory sentence that is comprehensible to a wide audience.
- A more detailed background sentence that is relevant to likely readers.
- A sentence that states the general problem.
- Sentences that summarize and then explain the main results.
- A sentence about general context.
- And finally, a sentence about the broader perspective.
The first sentence of an abstract should not be vacuous. Assuming the reader continued past the title, this first sentence is the next opportunity that we have to implore them to keep reading our paper. And then the second sentence of the abstract, and so on. Work and re-work the abstract until it is so good that you would be fine if that was the only thing that was read; because that will often be the case.
4.5.3 Introduction
An introduction needs to be self-contained and convey everything that a reader needs to know. We are not writing a mystery story. Instead, we want to give away the most important points in the introduction. For a ten-to-fifteen-page paper, an introduction may be two or three paragraphs of main content. Hayot (2014, 90) says the goal of an introduction is to engage the reader, locate them in some discipline and background, and then tell them what happens in the rest of the paper. It should be completely reader-focused.
The introduction should set the scene and give the reader some background. For instance, we typically start a little broader. This provides some context to the paper. We then describe how the paper fits into that context, and give some high-level results, especially focused on the one key result that is the main part of the story. We provide more detail here than we provided in the abstract, but not the full extent. And we broadly discuss next steps in a sentence or two. Finally, we finish the introduction with an additional short final paragraph that highlights the structure of the paper.
As an example (with made-up details):
The UK Conservative Party has always done well in rural electorates. And the 2016 Brexit vote was no different with a significant difference in support between rural and urban areas. But even by the standard of rural support for conservative issues, support for “Vote Leave” was unusually strong with “Vote Leave” being most heavily supported in the East Midlands and the East of England, while the strongest support for “Remain” was in Greater London.
In this paper we look at why the performance of “Vote Leave” in the 2016 Brexit referendum was so correlated with rurality. We construct a model in which support for “Vote Leave” at a voting area level is explained by the number of farms in the area, the average internet connectivity, and the median age. We find that as the median age of an area increases, the likelihood that an area supported “Vote Leave” decreases by 14 percentage points. Future work could look at the effect of having a Conservative MP which would allow a more nuanced understanding of these effects.
The remainder of this paper is structured as follows: Section 2 discusses the data, Section 3 discusses the model, Section 4 presents the results, and finally Section 5 discusses our findings and some weaknesses.
The introduction needs to be self-contained and tell the reader almost everything that they need to know. A reader should be able to only read the introduction and have an accurate picture of all the major aspects of the whole paper. It would be rare to include graphs or tables in the introduction. An introduction should close by telegraphing the structure of the paper.
4.5.4 Data
Robert Caro, Lyndon Johnson’s biographer, describes the importance of conveying “a sense of place” when writing a biography (Caro 2019, 141). He defines this as “the physical setting in which a book’s action is occurring: to see it clearly enough, in sufficient detail, so that he feels as if he himself were present while the action is occurring.” He provides the following example:
When Rebekah walked out the front door of that little house, there was nothing—a roadrunner streaking behind some rocks with something long and wet dangling from his beak, perhaps, or a rabbit disappearing around a bush so fast that all she really saw was the flash of a white tail—but otherwise nothing. There was no movement except for the ripple of the leaves in the scattered trees, no sound except for the constant whisper of the wind\(\dots\) If Rebekah climbed, almost in desperation, the hill in the back of the house, what she saw from its crest was more hills, an endless vista of hills, hills on which there was visible not a single house\(\dots\) hills on which nothing moved, empty hills with, above them, empty sky; a hawk circling silently overhead was an event. But most of all, there was nothing human, no one to talk to.
Caro (2019, 146)
How thoroughly we can imagine the circumstances of Johnson’s mother, Rebekah Baines Johnson. When writing our papers, we need to achieve that same sense of place, for our data, as Caro provides for the Hill County. We do this by being as explicit as possible. We typically have a whole section about it and this is designed to show the reader, as closely as possible, the actual data that underpin our story.
When writing the data section, we are beginning our answer to the critical question about our claim, which is, how is it possible to know this? (McPhee 2017, 78). An excellent example of a data section is provided by Doll and Hill (1950). They are interested in the effect of smoking between control and treatment groups. After clearly describing their dataset they use tables to display relevant cross-tabs and graphs to contrast groups.
In the data section we need to thoroughly discuss the variables in the dataset that we are using. If there are other datasets that could have been used, but were not, then this should be mentioned and the choice justified. If variables were constructed or combined, then this process and motivation should be explained.
We want the reader to understand what the data that underpin the results look like. This means that we should graph the data that are used in our analysis, or as close to them as possible. And we should also include tables of summary statistics. If the dataset was created from some other source, then it can also help to include an example of that original source. For instance, if the dataset was created from survey responses then the underlying survey questions should be included in an appendix.
Some judgment is required when it comes to the figures and tables in the data section. The reader should have the opportunity to understand the details, but it may be that some are better placed in an appendix. Figures and tables are a critical aspect of convincing people of a story. In a graph we can show the data and then let the reader decide for themselves. And using a table, we can summarize a dataset. At the very least, every variable should be shown in a graph and summarized in a table. If there are too many, then some of these could be relegated to an appendix, with the critical relationships shown in the main body. Figures and tables should be numbered and then cross-referenced in the text, for instance, “Figure 1 shows\(\dots\)”, “Table 1 describes\(\dots\)”. For every graph and table there should be accompanying text that describes their main aspects, and adds additional detail.
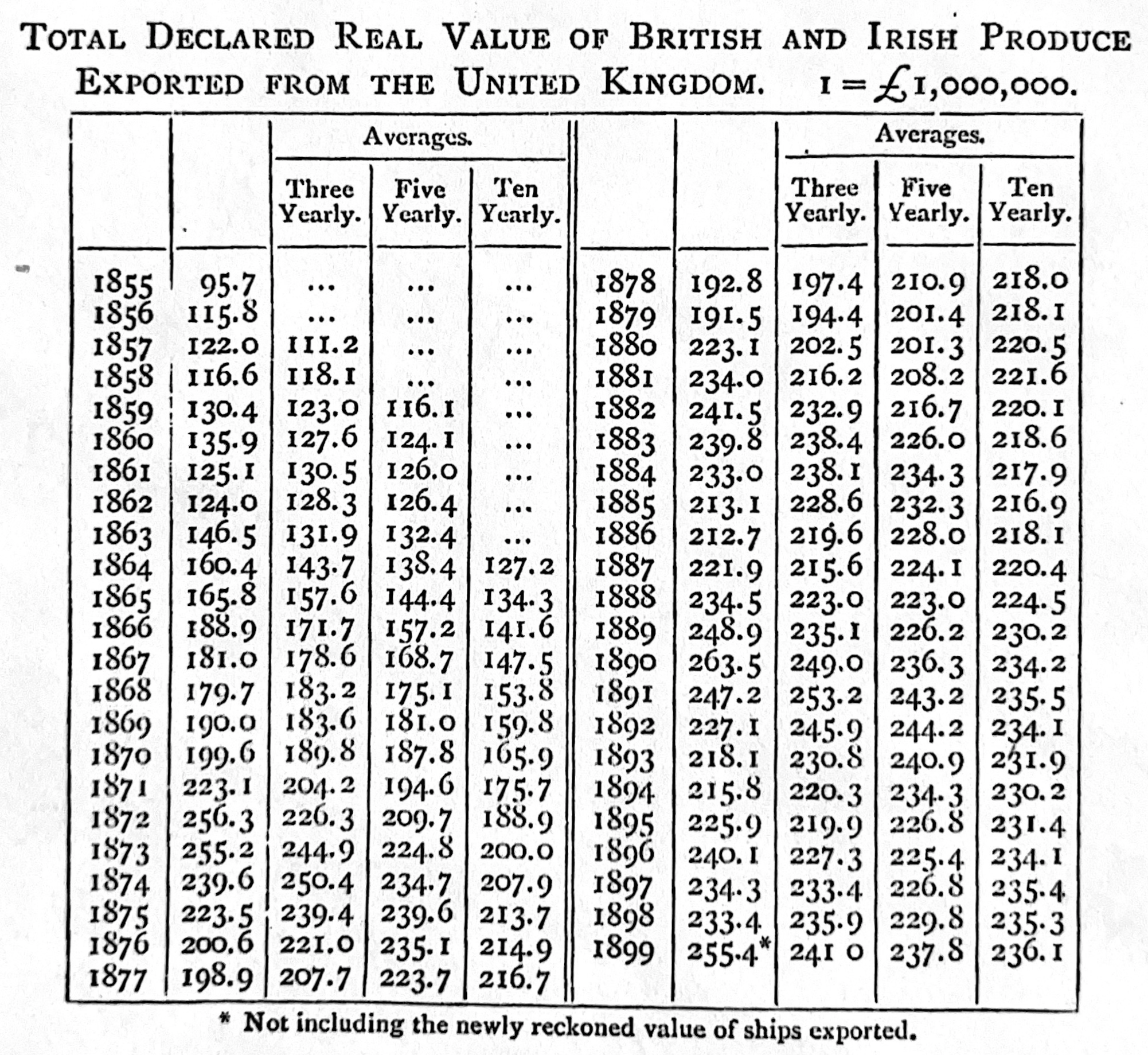
We discuss the components of graphs and tables, including titles and labels, in Chapter 5. But here we will discuss captions, as they are between the text and the graph or table. Captions need to be informative and self-contained. Borkin et al. (2015) use eye-tracking to understand how visualizations are recognized and recalled. They find that captions need to make the central message of the figure clear, and that there should be redundancy. As Cleveland ([1985] 1994, 57) says, the “interplay between graph, caption, and text is a delicate one”, however the reader should be able to read only the caption and understand what the graph or table shows. A caption that is two lines long is not necessarily inappropriate. And all aspects of the graph or table should be explained. For instance, consider Figure 4.5 (a) and Figure 4.5 (b), both from Bowley (1901, 151). They are clear, and self-contained.
The choice between a table and a graph comes down to how much information is to be conveyed. In general, if there is specific information that should be considered, such as a summary statistic, then a table is a good option. If we are interested in the reader making comparisons and understanding trends, then a graph is a good option (Gelman, Pasarica, and Dodhia 2002).
4.5.5 Model
We often build a statistical model that we will use to explore the data, and it is normal to have a specific section about this. At a minimum you should specify the equations that describe the model being used and explain their components with plain language and cross-references.
The model section typically begins with the model being written out, explained, and justified. Depending on the expected reader, some background may be needed. After specifying the model with appropriate mathematical notation and cross-referencing it, the components of the model should then be defined and explained. Try to define each aspect of the notation. This helps convince the reader that the model was well-chosen and enhances the credibility of the paper. The model’s variables should correspond to those that were discussed in the data section, making a clear link between the two sections.
There should be some discussion of how features enter the model and why. Some examples could include:
- Why use age rather than age-groups?
- Why does state/province have a levels effect?
- Why is gender a categorical variable? In general, we are trying to convey a sense that this is the appropriate model for the situation. We want the reader to understand how the aspects that were discussed in the data section assert themselves in the modeling decisions that were made.
The model section should close with some discussion of the assumptions that underpin the model. It should also have a brief discussion of alternative models or variants. You want the strengths and weaknesses to be clear and for the reader to know why this particular model was chosen.
At some point in this section, it is usually appropriate to specify the software that was used to run the model, and to provide some evidence of thought about the circumstances in which the model may not be appropriate. That second point would typically be expanded on in the discussion section. And there should be evidence of model validation and checking, model convergence, and/or diagnostic issues. Again, there is a balance needed here, and some of this content may be more appropriately placed in appendices.
When technical terms are used, they should be briefly explained in plain language for readers who might not be familiar with it. For instance, M. Alexander (2019) integrates an explanation of the Gini coefficient that brings the reader along.
To look at the concentration of baby names, let’s calculate the Gini coefficient for each country, sex and year. The Gini coefficient measures dispersion or inequality among values of a frequency distribution. It can take any value between 0 and 1. In the case of income distributions, a Gini coefficient of 1 would mean one person has all the income. In this case, a Gini coefficient of 1 would mean that all babies have the same name. In contrast, a Gini coefficient of 0 would mean names are evenly distributed across all babies.
There may be papers that do not include a statistical model. In that case, this “Model” section should be replaced by a broader “Methodology” section. It might describe the simulation that was conducted, or contain more general details about the approach.
4.5.6 Results
Two excellent examples of results sections are provided by Kharecha and Hansen (2013) and Kiang et al. (2021). In the results section, we want to communicate the outcomes of the analysis in a clear way and without too much focus on the discussion of implications. The results section likely requires summary statistics, tables, and graphs. Each of those aspects should be cross-referenced and have text associated with them that details what is seen in each figure. This section should relay results; that is, we are interested in what the results are, rather than what they mean.
This section would also typically include tables of graphs of coefficient estimates based on the modeling. Various features of the estimates should be discussed, and differences between the models explained. It may be that different subsets of the data are considered separately. Again, all graphs and tables need to have text in plain language accompany them. A rough guide is that the amount of text should be at least equal to the amount of space taken up by the tables and graphs. For instance, if a full page is used to display a table of coefficient estimates, then that should be cross-referenced and accompanied by about a full page of text about that table.
4.5.7 Discussion
A discussion section may be the final section of a paper and would typically have four or five sub-sections.
The discussion section would typically begin with a sub-section that comprises a brief summary of what was done in the paper. This would be followed by two or three sub-sections that are devoted to the key things that we learn about the world from this paper. These sub-sections are the main opportunity to justify or detail the implications of the story being told in the paper. Typically, these sub-sections do not see newly introduced graphs or tables, but are instead focused on what we learn from those that were introduced in earlier sections. It may be that some of the results are discussed in relation to what others have found, and differences could be attempted to be reconciled here.
Following these sub-sections of what we learn about the world, we would typically have a sub-section focused on some of the weaknesses of what was done. This could concern aspects such as the data that were used, the approach, and the model. In the case of the model we are especially concerned with those aspects that might affect the findings. This can be especially difficult in the case of machine learning models and Smith et al. (2022) provide guidance for aspects to consider. And the final sub-section is typically a few paragraphs that specify what is left to learn, and how future work could proceed.
In general, we would expect this section to take at least 25 per cent of the total paper. This means that in an eight-page paper we would expect at least two pages of discussion.
4.5.8 Brevity, typos, and grammar
Brevity is important. This is partly because we write for the reader, and the reader has other priorities. But it is also because as the writer it forces us to consider what our most important points are, how we can best support them, and where our arguments are weakest. Jean Chrétien, is a former Canadian prime minister. In Chrétien (2007, 105) he wrote that he used to ask “\(\dots\)the officials to summarize their documents in two or three pages and attach the rest of the materials as background information. I soon discovered that this was a problem only for those who didn’t really know what they were talking about” .
This experience is not unique to Canada and it is not new. In Hughes and Rutter (2016) Oliver Letwin, the former British cabinet member, describes there being “a huge amount of terrible guff, at huge, colossal, humongous length coming from some departments” and how he asked “for them to be one quarter of the length”. He found that the departments were able to accommodate this request without losing anything important. Winston Churchill asked for brevity during the Second World War, saying “the discipline of setting out the real points concisely will prove an aid to clearer thinking.” The letter from Szilard and Einstein to FDR that was the catalyst for the Manhattan Project was only two pages!
Zinsser (1976) goes further and describes “the secret of good writing” being “to strip every sentence to its cleanest components.” Every sentence should be simplified to its essence. And every word that does not contribute should be removed.
Unnecessary words, typos, and grammatical issues should be removed from papers. These mistakes affect the credibility of claims. If the reader cannot trust you to use a spell-checker, then why should they trust you to use logistic regression? RStudio has a spell-checker built in, but Microsoft Word and Google Docs are useful additional checks. Copy from the Quarto document and paste into Word, then look for the red and green lines, and fix them in the Quarto document.
We are not worried about the n-th degree of grammatical content. Instead, we are interested in grammar and sentence structure that occurs in conversational language use (S. King 2000, 118). The way to develop comfort is by reading widely and asking others to also read your work. Another useful tactic is to read your writing aloud, which can be useful for detecting odd sentences based on how they sound. One small aspect to check that will regularly come up is that any number from one to ten should be written as words, while 11 and over should be written as numbers.
4.5.9 Rules
A variety of authors have established rules for writing. This famously includes those of Orwell (1946) which were reimagined by The Economist (2013). A further reimagining of rules for writing, focused on telling stories with data, could be:
- Focus on the reader and their needs. Everything else is commentary.
- Establish a structure and then rely on that to tell the story.
- Write a first draft as quickly as possible.
- Rewrite that draft extensively.
- Be concise and direct. Remove as many words as possible.
- Use words precisely. For instance, stock prices rise or fall, rather than improve or worsen.
- Use short sentences where possible.
- Avoid jargon.
- Write as though your work will be on the front page of a newspaper.
- Never claim novelty or that you are the “first to study X”—there is always someone else who got there first.
Fiske and Kuriwaki (2021) have a list of rules for scientific papers and the appendix of Pineau et al. (2021) provides a checklist for machine learning papers. But perhaps the last word should be from Savage and Yeh (2019):
[T]ry to write the best version of your paper: the one that you like. You can’t please an anonymous reader, but you should be able to please yourself. Your paper—you hope—is for posterity.
Savage and Yeh (2019, 442)
4.6 Exercises
Practice
- (Plan) Consider the following scenario: A child and their parent watch street cars from their apartment window. Every hour, for eight hours, they record the number of streetcars that go past. Please sketch what a dataset could look like, and then sketch a graph that you could build to show all observations.
- (Simulate) Please further consider the scenario described and simulate the situation. Then write five tests based on the simulated data.
- (Acquire) Please specify a source of actual data about some aspect of public transportation in a city that you are interested in.
- (Explore) Build a graph and table using the simulated data.
- (Share) Please write some text to accompany the graph and table, as if they reflected the actual situation. The exact details contained in the paragraphs do not have to be factual but they should be reasonable (i.e. you do not actually have to get the data nor create the graphs). Separate the code appropriately into
Rfiles and a Quarto doc. Submit a link to a GitHub repo with a README.
Quiz
- What are three features of a good research question (write a paragraph or two)?
- How do Light, Singer, and Willett (1990) recommend going from a broad theme to planning a study in detail (pick one)?
- Talk to experts.
- Identify available data.
- Articulate a set of specific research questions.
- Why do Light, Singer, and Willett (1990) believe research questions are so important (select all that apply)?
- They are the only basis for making sensible planning decisions.
- They identify the target population from which you will draw a sample.
- They determine the appropriate level of aggregation.
- They identify the outcome variable.
- They identify the key predictors.
- They raise challenges for measurement and data collection.
- From Light, Singer, and Willett (1990), what is the purpose of the “spiral of theory and data” in research (pick one)?
- To collect the data before developing theories.
- To iteratively refine both theory and data by moving between them.
- To ensure data collection is completed before any theoretical analysis.
- To focus solely on theoretical frameworks without data.
- In the context of research approaches, what does data-first mean (pick one)?
- Developing research questions without considering data availability.
- Collecting new data specifically designed to answer a predefined question.
- Prioritizing theoretical frameworks over empirical evidence.
- Starting with available data and then determining the questions that can be answered.
- What is an advantage of a data-first approach (pick one)?
- It eliminates the need for theoretical frameworks.
- It allows researchers to formulate questions based on available data.
- It guarantees causal relationships can be established.
- It prevents any form of bias in the research.
- What is a disadvantage of a data-first approach (pick one)?
- The concern that you are “searching under the streetlight”.
- The concern about being able to contribute to theory.
- The concern that causality will be difficult to tease apart.
- The concern about external validity.
- What is a counterfactual (include examples and references and write at least three paragraphs)?
- What is a counterfactual (pick one)?
- An alternative hypothesis that contradicts the main theory.
- An if-then statement in which the if is false.
- A fact that counters the main argument of the paper.
- A statistical method used to adjust for confounding variables.
- What does the “FINER” framework stand for (pick one)?
- Flexible, Innovative, Neutral, Empirical, Replicable.
- Formal, Interpretive, New, Experimental, Robust.
- Focused, Integrated, Natural, Efficient, Reliable.
- Feasible, Interesting, Novel, Ethical, Relevant.
- What is an estimand (pick one)?
- A variable that is measured with error.
- A biased estimator.
- The process of using data to calculate an estimate.
- The true effect or quantity of interest that we aim to estimate.
- What is an estimand (pick one)?
- A rule for calculating an estimate of a given quantity based on observed data.
- The object of inquiry.
- A result given a particular dataset and approach.
- What is an estimator (pick one)?
- A rule for calculating an estimate of a given quantity based on observed data.
- The object of inquiry.
- A result given a particular dataset and approach.
- What is the role of an estimator (pick one)?
- It is the true effect we aim to estimate.
- It is a rule or method for calculating an estimate from data.
- It is a calculated value given a dataset and method.
- It is an error term in the statistical model.
- What is an estimate (pick one)?
- A rule for calculating an estimate of a given quantity based on observed data.
- The object of inquiry.
- A result given a particular dataset and approach.
- What is selection bias (pick one)?
- When participants drop out of a study over time.
- When results are affected by how data are measured.
- When the sample is not representative of the population.
- When variables are not properly controlled in an experiment.
- What is measurement bias (pick one)?
- When data are inaccurately recorded due to equipment failure.
- When the data collection method systematically overstates or understates the true value.
- When the process of measuring influences the results.
- When the sample size is too small to draw conclusions.
- What is the purpose of Directed Acyclic Graphs (DAGs) (pick one)?
- To create random samples from complex populations.
- To perform statistical tests on non-linear data.
- To automatically generate statistical models.
- To visually represent causal relationships between variables.
- What is a benefit of building a DAG (pick one)?
- They automatically identify causal relationships in data.
- They eliminate the need for statistical analysis.
- They help researchers think carefully about variable relationships.
- They provide precise estimates of causal effects.
- What is a confounder (pick one)?
- A variable that is influenced by both the predictor and outcome variable.
- A variable that affects both the predictor and outcome variables.
- A variable that is affected by the predictor and affects the outcome variable.
- What is a mediator (pick one)?
- A variable that is influenced by both the predictor and outcome variable.
- A variable that affects both the predictor and outcome variables.
- A variable that is affected by the predictor and affects the outcome variable.
- What is a collider (pick one)?
- A variable that is influenced by both the predictor and outcome variable.
- A variable that affects both the predictor and outcome variables.
- A variable that is affected by the predictor and affects the outcome variable.
- According to Chapter 2 of Zinsser (1976), what is the secret to good writing (pick one)?
- Correct sentence structure and grammar.
- The use of long words, adverbs, and passive voice.
- Strip every sentence to its cleanest components.
- Thorough planning.
- According to Chapter 2 of Zinsser (1976), what must a writer constantly ask (pick one)?
- Who am I writing for?
- What am I trying to say?
- How can this be rewritten?
- Why does this matter?
- What is one of the critical tasks in the process of writing a paper (pick one)?
- Gathering as much data as possible before starting to write.
- Spending extensive time perfecting each sentence in the first draft.
- Getting to a first draft as quickly as possible.
- Focusing on creating detailed graphs and tables before writing.
- Why is getting to a first draft quickly important (pick one)?
- It ensures that no mistakes are made in the initial draft.
- It provides a complete version to revise and improve on.
- It allows the writer to perfect each sentence as they go.
- It reduces the overall time spent on writing.
- What does “kill your darlings” mean (pick one)?
- To avoid writing about controversial topics.
- To use harsh criticism to improve your work.
- To remove unnecessary content you are fond of but that doesn’t serve the main story.
- To rewrite the entire draft from scratch.
- Which of the following is a key benefit of writing for the writer, even when the focus is on the reader (pick one)?
- It allows the writer to avoid rewriting the paper.
- It helps the writer to work out what they believe and how they came to believe it.
- It reduces the amount of feedback required from peers.
- It ensures that the writer’s work will be published.
- Which two repeated words, for instance in Chapter 3, characterize the advice of Zinsser (1976) (pick one)?
- Rewrite, rewrite.
- Simplify, simplify.
- Remove, remove.
- Less, less.
- What is the main reason for removing unnecessary words, typos, and grammatical issues from a paper (pick one)?
- To meet word count limits.
- To impress reviewers with advanced vocabulary.
- To make the paper longer.
- To enhance the credibility of the claims.
- Which of the following is the best title (pick one)?
- “Standard errors of estimates from small samples”
- “Standard errors”
- “Problem Set 2”
- What is one strategy for writing a title (pick one)?
- Use technical jargon to impress expert readers.
- Include both the general topic and specific information about the main finding.
- Make it as short as possible, using only one or two words.
- Pose the title as a question to engage the reader.
- Please write a new title for Fourcade and Healy (2017).
- Which of the following is NOT recommended when writing an abstract (pick one)?
- Adding figures or tables to illustrate key points.
- Including the main results and implications.
- Using precise and concise language.
- Making the abstract self-contained.
- What is a common structure for writing an abstract (pick one)?
- Start with implications, then methods, and end with context.
- First sentence about the general area, second about methods, third about main result, fourth about implications.
- Begin with limitations, followed by data sources, then results.
- A series of questions that the paper will answer.
- Using only the 1,000 most popular words in the English language, according to the XKCD Simple Writer, rewrite the abstract of Chambliss (1989) so that it retains its original meaning.
- According to G. King (2006), what is the key task of subheadings (pick one)?
- Use acronyms to integrate the paper into the literature.
- Be broad and sweeping so that a reader is impressed by the importance of the paper.
- Enable a reader who randomly falls asleep but keeps turning pages to know where they are.
- What do you want to achieve by from the data section (pick one)?
- To demonstrate the complexity of the data to impress the reader.
- To create a sense of place by thoroughly describing the data.
- To include as many graphs and tables as possible.
- To hide any weaknesses in the data.
- What is the primary goal of the data section in a research paper (pick one)?
- To present as many tables and graphs as possible.
- To thoroughly describe the data so the reader understands the basis of the results.
- To convince the reader of the complexity of the analysis.
- To discuss all possible data sources, even those not used.
- According to G. King (2006), if our standard error was 0.05 then which of the following specificities for a coefficient would be silly (select all that apply)?
- 2.7182818
- 2.718282
- 2.71828
- 2.7183
- 2.718
- 2.72
- 2.7
- 3
- What should a good figure or table caption accomplish (pick one)?
- Be as brief as possible, ideally one line.
- Be self-contained and explain the main take-away.
- Include complex jargon to demonstrate expertise.
- Provide minimal information to encourage the reader to read the text.
- What should be in the model section (pick one)?
- A summary of other models used in the literature.
- Only the final results without any equations.
- A general description without mathematical notation.
- The equations, explanations, and definitions of all components.
- Why is it important to discuss alternative models or variants in the model section (pick one)?
- To demonstrate thorough consideration and justify the chosen model.
- To show that other models are inferior.
- To confuse the reader with multiple options.
- To increase the length of the paper.
- What is purpose of the results section (pick one)?
- Interpreting the results and discussing their implications.
- Critiquing other researchers’ findings.
- Proposing future research directions.
- Presenting the outcomes of the analysis clearly, without extensive interpretation.
- In the results section, how should graphs and tables be integrated (pick one)?
- They should stand alone without any accompanying text.
- They should be minimized to avoid clutter.
- They should be cross-referenced and discussed in the text.
- They should be placed in an appendix to avoid interrupting the flow.
- What is the purpose of the discussion section (pick one)?
- To repeat the results in more detail.
- To provide a detailed methodology.
- To interpret the results, discuss implications, and acknowledge weaknesses.
- To list all the limitations of the study without offering solutions.
- Why does Savage and Yeh (2019) recommend asking yourself if it is possible to preserve your original message without that punctuation mark, that word, that sentence, that paragraph or that section (pick one)?
- To reduce the possibility of errors.
- To achieve clarity.
- To keep the paper short.
- What are key aspects of the re-drafting process (select all that apply)?
- Going through it with a red pen to remove unneeded words.
- Printing the paper and reading a physical copy.
- Cutting and pasting to enhance flow.
- Reading it aloud.
- Exchanging it with others.
- Why do poor grammar and typos affect the credibility of a paper (pick one)?
- They enhance the casual tone of the paper.
- They make the paper shorter.
- They indicate a lack of attention to detail.
- They are acceptable as long as the content is good.
Class activities
- Discuss your preferred approach (data-first/question-first/other) to research and why.
- Explain, with reference to examples, what is an estimand, estimator, and estimate.
- Please consider “selection bias” and include the definition in a sentence in the same way that M. Alexander (2019) does for the Gini coefficient.
- Please use ChatGPT, or an equivalent LLM, to create a prompt that answers the question “What is a selection effect?”. With a partner, improve the response by adding context, references, and making it true (if necessary). Discuss three aspects: 1) the prompt, 2) the original answer, 3) your augmented answer.
- Pick one of the well-written quantitative papers:
- Write out the original title. What do you like, and not like, about it? Write an alternative title for it.
- Write out the abstract. What do you like, and not like, about it?
- Please prompt ChatGPT, or an equivalent LLM, to create an alternative abstract (copy the prompt so you can discuss it).
- Draw on all of this to put together an improved abstract and then discuss everything.
- Make a plan, based on G. King (2006), for how you will write a meaningful paper by the end of this class. (For PhD students: Detail three journals/conferences, in order, that you will submit it to, and why the paper would be a good fit at each.)
- Paper review: Please read Gerring (2012) and write a review of one page.
Task
Caro (2019, xii) writes at least 1,000 words almost every day. The purpose of this task is to give you the chance to do that also. Please pick one of the papers specified in the prerequisites and complete the following tasks:
- Day 1: Transcribe, by writing each word yourself, the entire introduction.
- Day 2: Rewrite the introduction so that it is five lines (or 10 per cent, whichever is less) shorter.
- Day 3: Transcribe, by writing each word yourself, the abstract.
- Day 4: Rewrite a new, four-sentence, abstract for the paper.
- Day 5: Write a second version of your new abstract using only the 1,000 most popular words in the English language as defined here.
- Day 6: Detail three points about the way the paper is written that you like
- Day 7: Detail one point about the way the paper is written that you do not like.
Use Quarto build up a single PDF over the course of the week. After each day commit and push your work with an informative commit message. Make use of headings and sub-headings to structure your submission. Submit a link to your high-quality repo.
While there is sometimes a need for a separate literature review section, another approach is to discuss relevant literature throughout the paper as appropriate. For instance, when there is literature relevant to the data then it should be discussed in this section, while literature relevant to the model, results, or discussion should be mentioned as appropriate in those sections.↩︎